

M1 맥 출시 이후, 여러 벤치마킹 수치와 실사용기들이 M1 맥의 압도적인 성능을 이야기 하고 있다.
어떻게 갑자기 이렇게 강력한 하드웨어의 등장이 가능했을까?
압도적인 M1 칩의 성능이 밝혀지면서 이제는 호환성 문제만 해결되면 무조건 M1 맥으로 옮겨가는게 당연하다는 의견이 주류가 되었다.
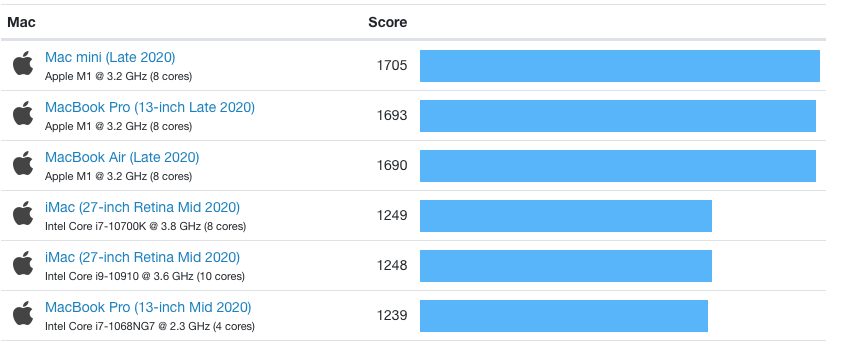
M1 맥 싱글코어 벤치마킹, 데스크탑과 랩탑을 통틀어 최상위권이다.
또한 애플이 제공하는 맥 전용 소프트웨어(ex. 파이널컷)들은 이미 M1 맥북에 최적화가 되어 있기 때문에, 주로 사용하는 소프트웨어가 그런것들인 맥북 사용자들은 당장 오늘 M1 맥북으로 갈아타는게 합리적으로 보일 정도이다.
그런데 ARM 프로세서 기반 CPU를 탑재한 랩탑의 출시는 M1 이전에도 여러번 있었지만, 이정도의 압도적 성능을 보여주진 못하였다.
대체 M1은 어떻게 이런 비약적인 성능 발전을 가져올 수 있었는지 설명한 좋은 글이 있어 번역해 보았다.
원문 : Why Is Apple’s M1 Chip So Fast?
옮긴이의 들어가기 전 짤막 지식
원문 글에서도 완~전 기본적인 내용은 설명하지 않는데, 들어가기 전 사전 지식을 간단히 짚어보자.
- 맥북은 지금까지는 Intel 기반 CPU를 사용해 왔는데, 여러가지 문제 (업그레이드 느림, 발열 문제)가 있어왔어서 자체 개발한 M1 칩으로 갈아타는것을 발표하였다.
- M1에서 사용하는 CPU는 ARM 프로세서 기반이다.
- 현대 CPU는 크게 두가지로 나뉜다, RISC vs CISC
- RISC (Reduced Instruction Set Computer) : ARM에서 주로 사용. 쉽게생각해 CPU가 실행하는 instruction 형태와 갯수가 단순하다. Instruction마다 길이가 같다.
- CISC (Complex Instruction Set Computer) : Intel, AMD에서 주로 사용. 쉽게 생각해 CPU가 실행하는 instruction 형태와 갯수가 복잡하다. Instruction마다 길이가 다르다.
Why Is Apple’s M1 Chip So Fast?
저는 작년에 유튜브에서 4000 달러 정도를 들여 40GB 램이 장착된 iMac을 구입한 사람을 보았습니다. 올해는 그 사람이 그 값비싼 iMac이 자기가 고작 700 달러 주고 산 새 M1 Mac Mini에게 처참히 무너지는것을 눈물흘리며 보고 있었습니다.
여러 실 사용 테스트를 보면, M1 맥은 지금까지의 하이엔드 인텔 맥을 앞서는 정도가 아니라 그냥 압살하고 있습니다. 이런 믿을수 없는 모습에 사람들은 도대체 어떻게 이런게 가능한지 궁금해 하고 있습니다.
여러분도 그렇게 궁금해 하고 있었다면, 딱 알맞은 곳에 찾아오셨습니다. 이 글에서는 애플이 M1을 가지고 정확히 무엇을 했는지 몇가지 이해하기 쉬운 부분들로 나누어 설명해 보고자 합니다. 구체적으로, 아마 여러분들은 아래와 같은 의문을 갖고 있을 것 입니다.
- M1 칩이 그렇게 빠를 수 있는 기술적인 이유?
- 이걸 위해 애플이 아주 기상천외한 기술을 사용했는지? (역: 외계인 고문?)
- 인텔이나 AMD가 비슷한 기술을 가져와서 경쟁을 시작할 가능성이 얼마나 되는지?
물론 이러한 질문들을 구글링 해 볼수 있겠지만, 애플이 무엇을 했는지 표면적인 설명을 넘어 이해하려 하다 보면 Instruction Decoders, Reorder Buffer 등등 매우 기술적인 이야기들에 둘러쌓여 버릴 것 입니다. 여러분이 CPU 하드웨어 오타쿠가 아니라면 이런 내용은 그냥 이해할 수 없는 이야기겠지요.
이 이야기를 제대로 이해하려면 제가 이전에 쓴 글을 읽어보는것을 추천드립니다: “What Does RISC and CISC Mean in 2020?“. 해당 글에서는 microprocessor (CPU)가 무엇인지, 그리고 아래와 같은 몇가지 중요한 컨셉을 설명하고 있습니다.
- Instruction Set Architecture (ISA)
- Pipelining
- Load/Store architecture
- Microcode vs Micro-operations
읽기 귀찮으신 분들을 위해, 이글에서도 짧게나마 제가 쓴 M1칩에 대한 설명을 이해하는데 필요한 내용들을 알려드리겠습니다.
Microprocessor (CPU)란 무엇인가?
일반적으로 인텔이나 AMD에서 제조한 칩(Chip)에 대해 이야기 할때, 이는 Centrual Processing Units (CPUs) 또는 Microprocessors를 가리킵니다. 제가 쓴 글 RISC vs. CISC story 에서 알 수 있다 시피, 이들은 메모리에서 명령어(instruction)를 불러(pull) 옵니다. 그 다음 일반적으로 각 instruction은 일련의 과정을 거치게 됩니다.
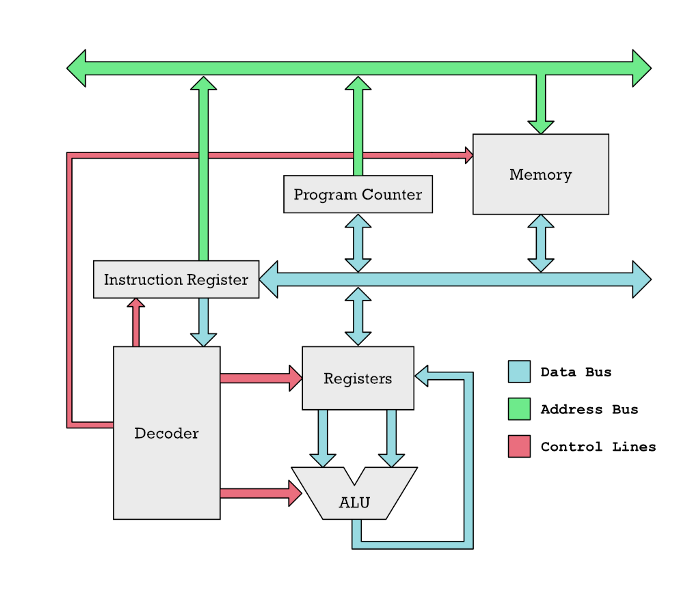
매우 기본적인 RISC CPU (M1 아님). Instruction은 파란 화살표를 따라 Memory에서 Registers로 이동됨. Decoder는 각 instruction이 무엇인지 판단하고, 빨간 화살표로 표시된 Control Lines를 통해 CPU의 여러 파트를 활성화 함. ALU는 Registers에 위치한 값들에 덧셈이나 뺼셈을 수행함.
CPU는 가장 기본적인 수준에서 보면, 레지스터(register)라 불리는 개별 이름이 있는 메모리 구역 (memory cell) 여러개와 산술 논리 장치 (arithmetic logic unit, ALU)라 불리는 연산 유닛 여러개로 이루어진 장치입니다.
ALU는 덧셈, 뺄셈, 그리고 다른 기본적인 수학적인 연산을 수행합니다. 하지만 이들은 CPU에만 연결되어 있습니다. 두개의 숫자를 더하기 위해서는, 이 두 숫자를 메모리로부터 CPU 내부의 두개의 레지스터로 가져와야 합니다.
아래는 M1이 수행하는 전형적인 RISC CPU 연산입니다.
1 | load r1, 150 |
여기서 r1, r2는 앞서 언급한 레지스터입니다. 현대 RISC CPU는 레지스터에 있지 않은 숫자로는 연산을 수행하지 못합니다. 예를 들어 RAM 위의 두곳의 다른 위치에 있는 숫자를 더하는것은 불가능 합니다. 대신, 두 숫자를 불러와서(pull) 개별적으로 레지스터에 저장한 다음에 해당 레지스터에 들어있는 값 끼리 더하는것은 가능합니다. 그리고 위 예제에서 수행하는것이 바로 그것입니다. 먼저 RAM위의 메모리 위치 150에 존재하는 값을 불러와 CPU 내의 r1 레지스터에 저장합니다. 그 다음 메모리 주소 200에 위치하는 값을 불러와 r2 레지스터에 저장합니다. 그 다음에야 비로서 두 숫자는 add r1, r2 instruction을 통해 더해질 수 있습니다.

두개의 레지스터 (accumulator register와 input register)를 가지고 있는 옛날 기계적 계산기. 현대 CPU들은 보통 열개가 넘는 레지스터를 가지고 있고, 기계적이지 않고 전기적이다.
레지스터라는 컨셉 자체는 오래된 것입니다. 예를 들어 위 사진에 나온 옛날 기계적 계산기는 덧셈에 사용될 두 숫자를 들고있는 두개의 레지스터를 가지고 있습니다. 이 용어는 아마 cash register (우리말 금전 등록기, 카운터에서 지폐,동전 넣는것)에서 유래한 것으로 보입니다. 레지스터는 인풋으로 쓰일 숫자를 등록(register)하는 곳 입니다!
M1은 CPU가 아닙니다!
여러분이 M1에 관해 알아야 할 아주 중요한 사실이 있습니다.
M1은 CPU가 아니라, 여러개의 칩이 하나의 거대한 실리콘 패키지에 넣어진 전체적인 시스템 입니다. CPU는 그 여러가지 칩들 중 하나일 뿐 입니다.
근본적으로, M1은 하나의 칩에 올려진 하나의 온전한 컴퓨터 입니다. M1은 CPU, 그래픽 처리 유닛 (graphical processing unit, GPU), 메모리, input & output 컨트롤러, 그리고 컴퓨터를 구성하는 많은 다른 요소들로 이루어 져 있습니다. 이것이 바로 System on a Chip (SoC)이라고 불리는 것 입니다.

M1은 System on a Chip 이다. 즉, 컴퓨터를 이루는 모든 구성요소가 하나의 실리콘 칩 위에 올라가있다.
오늘날 인텔이나 AMD로부터 칩을 구입하게 된다면, 실제로 받게 되는 것은 여러개의 microporcessor가 하나의 패키지에 포함된 것입니다. 예전에 컴퓨터는 물리적으로 분리된 여러개의 칩을 마더보드(메인보드)에 가지고 있었습니다.

컴퓨터 마더보드의 예시. 메모리, CPU, 그래픽 카드, IO 컨트롤러, 네트워크 카드, 그리고 많은 다른 구성요소들이 서로 통신하기 위해 마더보드에 연결된다.
하지만 요즘에는 엄청난 수의 트랜지스터를 실리콘 다이 (silicon die) 하나에 넣을 수 있기 때문에, 인텔이나 AMD같은 회사들은 여러개의 microprocessor를 하나의 칩 안에 넣기 시작했습니다. 이러한 칩들이 바로 CPU 코어 라고 불려지는 것 입니다. 하나의 코어는 기본적으로 메모리로부터 instruction을 읽어와 연산을 수행할 수 있는 완전히 독립적인 하나의 칩 입니다.

여러개의 CPU 코어를 가지는 하나의 마이크로칩(microchip)
이것이 바로 오랜 시간동안 성능 향상이라는 경쟁에서 핵심 요소였습니다. 즉, 성능 향상은 그냥 범용 CPU 코어(general-purpose CPU cores) 갯수를 늘리는 것이었습니다. 하지만 그러한 흐름에 변화가 있었습니다. 바로 CPU 시장에서의 한 플레이어가 이러한 트렌드에서 벗어나기 시작한것입니다.
애플의 그렇게 비밀스럽지 않은 혼합적 컴퓨팅(heterogeneous computing) 전략
범용 CPU 코어를 계속 늘려나가는 것 대신, 애플은 다른 전략을 수립하였습니다. 바로 좀 더 특화된 소수의 일을 하는 특화된 칩을 더 많이 추가하는 것입니다. 특화된 칩의 장점은 범용 CPU 코어에 비해 전력은 훨씬 덜 소모 하면서 일은 훨씬 더 빨리 할 수 있다는 것입니다.
이는 완전히 새로운 지식은 아니었습니다. 지난 수년간 GPU 같은 특화된 칩들은 Nvidia와 AMD 그래픽 카드에 올라가 그래픽에 관련된 연산들을 범용 CPU들보다 훨씬 더 빨리 처리해 왔습니다.
애플은 이걸 좀 더 과격하게 한 것 이었습니다. 그냥 범용 코어와 메모리를 몇개 갖는 대신, M1은 아래와 같이 매우 다양한 종류의 특화 칩들을 가지고 있습니다.
- Central processing unit (CPU) - SoC의 “두뇌” 역할. 운영체제나 어플리케이션에 사용되는 대부분의 코드를 돌림.
- Graphics processing unit (GPU) - 앱의 UI 표시, 2D/3D 게이밍 등등 그래픽 관련 일을 처리
- Image processing unit (ISP) - 이미지 처리 어플리케이션들이 사용하는 일반적인 일들의 속도를 높이는데 사용
- Diginal signal processor (DSP) - CPU보다 연산 집약적인 함수들을 다루는데 사용. 압축 해제 등등
- Neural processing unit (NPU) - 하이엔드 스마트폰 등에서 기계학습 (A.I.) 속도를 높이는데 사용. 예를들어 음성인식, 이미지 처리 등등
- Video encoder/decoder - 전력 효율적으로 비디오 파일이나 포맷을 변환하는 작업 수행
- Secure Enclave - 암호화, 인증, 그 외 보안 관련 작업을 수행하는 영역
- Unified memory - CPU, GPU와 다른 코어들이 빠르게 정보를 교환하는게 가능한 메모리
위 요소들이 왜 이미지나 영상 편집을 주로 하는 많은 사용자들이 M1 맥에서 엄청난 속도 향상을 느끼는지에 대한 이유중 하나입니다. 그런 사용자들이 하는 일 중 많은 부분을 특화된 하드웨어 위에서 직접적으로 돌릴 수 있기 때문입니다. 그것이 바로 값비싼 iMac이 비행기 이륙하는 소리를 내는 동안 저렴한 M1 맥 미니가 땀 한방울 안흘리고 대용량 비디오 파일을 인코딩 할 수 있는 이유입니다.

파란색 부분은 여러개의 CPU 코어가 메모리에 접근하는것을 나타내며, 초록색 부분은 엄청난 수의 GPU 코어가 메모리에 접근하는것을 나타낸다.
애플의 통합 메모리 아키텍쳐 (Unified Memory Architecture)는 뭐가 그렇게 특별할까?
애플의 “Unified Memory Architecture” (UMA)는 이해하기에 약간 어려울 수 있습니다. (저 또한 처음 이 글을 적을 때 잘못 이해하고 있었습니다)
그 이유를 설명하기 위해서, 몇발자국 물러서서 바라 볼 필요가 있습니다.
오랜 시간동안 저렴한 컴퓨터 시스템은 CPU와 GPU를 하나의 칩(같은 실리콘 다이) 안에 가지고 있어왔습니다. 이러한 시스템은 느린것으로도 잘 알려져 있었습니다. 과거에는 “내장 그래픽(integrated graphics)” 이라 하면 “느린 그래픽(slow graphics)”과 동일한 의미로 사용되었을 정도니까요.
내장 그래픽이 느린데에는 다음과 같은 이유가 있었습니다.
우선 메모리 내에서 CPU와 GPU를 위해 별개의 영역이 예약되어야 했습니다. (역: 내장그래픽을 쓰면 램 일부가 하드웨어 예약으로 잡힌다.) 만약 CPU가 GPU에서 사용되길 원하는 데이터 덩어리(chunk)가 있으면 단순히 “야 GPU, 내 메모리 이 부분에 있는 데이터 가져다 써” 라고 할 수 없었습니다. 그 대신, CPU는 데이터 덩어리를 통째로 다 복사하여 GPU가 제어하는 메모리 영역으로 넘겨주어야 했습니다.

CPU는 데이터를 대량으로 제공받기 보다 빠르게 제공받기를 원한다.
CPU와 GPU는 같은 방식으로 메모리를 제공받기를 원하지 않습니다. 좀 웃기긴 하지만 음식을 가지고 비유를 해 보겠습니다. CPU는 데이터가 담겨있는 식사를 웨이터가 아주 빠르게 서빙해 주길 바라지만, 데이터의 양에 대해서는 크게 신경쓰지 않습니다. 웨이터가 롤러블레이드를 타고 아주 빠른 속도로 서빙을 하는 프랑스 레스토랑을 상상해 보세요.

GPU는 이렇게 메모리를 제공받길 원한다. 아주 대용량으로, 많으면 많을수록 GPU는 행복해요~😋
그와 반대로 GPU는 웨이터가 느릿느릿하게 데이터를 서빙하는데에 대해서는 아주 관대합니다. 대신, GPU는 아주 거대한 양을 서빙받길 원합니다. GPU는 대량의 데이터를 집어삼키는데, 그 이유는 GPU가 많은 양의 데이터를 동시에 먹어치울 수 있는 초대형 병렬 처리 기기이기 때문입니다. 미국 패스트푸드 식당을 상상해 보세요. 음식이 도착할 때 까지는 좀 걸리지만 여러분이 앉아 있는 곳까지 3단 카트에 음식이 한가득 실려 오고 있습니다.
이렇게 서로 다른 요구사항 때문에, CPU와 GPU를 같은 물리적 칩 위에 넣는것은 좋은 아이디어가 아니었습니다. 우리 GPU는 프랑스 레스토랑에서 제공하는 적은 양의 음식을 먹다 굶어 죽을것입니다. 결과적으로 강력한 GPU를 SoC에 넣는것은 큰 의미가 없었습니다. 매우 작은 양의 데이터가 GPU에게 제공되는데, 그정도는 작고 가벼운 GPU로도 충분히 처리할 수 있으니까요.
두번째 문제는 거대한 GPU는 많은 양의 열을 발생시키는데, 이 열을 해결하지 않고서는 CPU와 통합시킬 수 없다는 것입니다. 때문에 외장 그래픽 카드는 아래 사진처럼 무시무시한 쿨링 팬을 가진 거대한 짐승처럼 생기는 경향이 있습니다. 또한 욕심쟁이 외장 그래픽 카드에게 많은 양의 데이터를 제공할 수 있는 개별 메모리를 가지도록 디자인 되어 있습니다.

GeForce RTX 3080
그게 바로 이러한 그래픽 카드가 높은 성능을 가지고 있는 이유이기도 하지만, 아킬레스건을 가지고 있기도 합니다. 바로 CPU가 사용하는 메모리로부터 데이터를 가져올 때 입니다. 이 과정은 컴퓨터의 마더보드에 있는 PCIe 버스(bus)라 불리는 구리 선을 통해 일어나게 됩니다. 완전 얇은 빨대를 통해 물을 빨아먹는다고 생각 해 보세요. 입에 도착은 빨리 하겠지만, 물이 들어오는 속도는 처참하겠지요?
애플의 통합 메모리 아키텍쳐 (Unified Memory Architecture)는 이전의 공유 메모리가 가졌던 단점 없이 이러한 문제를 모두 해결하고자 합니다. 애플은 다음과 같은 방법으로 이를 달성하였습니다.
- CPU나 GPU만을 위해 예약된 전용 메모리 공간이 따로 없습니다. 둘 다 같은 메모리를 사용하며, 복사가 필요하지 않습니다.
- 애플은 대량의 데이터를 제공하고, 동시에 빠르기까지 한 메모리를 사용합니다. 이는 컴퓨터 전문 용어로 low latency, high throughput 이라고 합니다. 덕분에 다른 종류의 메모리가 연결되 있어야 할 필요가 없습니다.
- 애플은 GPU의 와트 사용량을 낮춤으로써 상대적으로 강력한 GPU도 과열 문제 없이 SoC에 통합될 수 있게 하였습니다. 또한 ARM 칩 자체의 열 발생량이 적기 때문에, AMD나 인텔 CPU를 사용하는 같은 실리콘 다이에 비해 GPU가 발생시키는 열을 좀 더 수용할 수 있었습니다.
물론 통합 메모리(unified memory) 자체는 완전히 새로운 것이 아니라고 이야기 하는 사람이 있을 수 있습니다. 이전에 다른 시스템에서 이러한 것들이 사용된 적이 있는 것은 사실입니다. 하지만 M1에 비해 메모리 요구량이 그렇게 많지 않았습니다. 둘째로, Nvidia가 통합 메모리 라고 부르던 것은 사실 같은것이 아닙니다. Nvidia 세계에서 통합 메모리는 단지 분리된 CPU와 GPU 메모리 사이에서 자동으로 데이터를 양방향으로 복사 해 주는 소프트웨어와 하드웨어가 있음을 의미하였습니다. 즉 프로그래머의 관점에서 애플과 Nvidia의 통합 메모리는 같아 보일 수 있지만, 사실 물리적 관점에서는 둘은 같지 않습니다.
물론 이러한 통합 메모리를 사용하는 것에는 장단점이 존재합니다. 대역폭이 높은 메모리(대량의 데이터 제공)는 하드웨어적으로 완전한 통합(integration)을 요구하는데, 이 경우 제품을 구매한 고객이 직접 메모리를 업그레이드 하는것이 불가능 해 집니다. 하지만 애플은 SSD 디스크와의 통신을 매우 빠르게 만듦으로써 사실상 기존의 메모리처럼 작동하게 하여 이러한 문제를 해결하고자 합니다.

통합 메모리 이전 맥이 GPU를 사용하던 방법. 심지어 썬더볼트3 케이블을 통해 컴퓨터 외부의 그래픽 카드를 사용할 수 있었다. 미래에 M1맥북에도 이러한 것이 가능할 것 이라는 고찰도 있다.
SoC가 그렇게 좋으면, 왜 인텔과 AMD는 이 전략을 따라하지 않을까?
애플이 하고있는게 그렇게 좋은것이라면, 왜 모두가 이 방법을 하고 있지 않을까요? 사실 이미 어느정도 그렇게 하고 있습니다. 다른 ARM 칩 제조사들은 점점 더 많은 특화된 하드웨어를 넣고 있습니다.
AMD또한 더 강력한 GPU를 그들의 칩 중 일부에 넣기 시작했으며, accelerated processing units (APU)를 통해 SoC와 비슷한 형태로 점차 옮겨가고 있는데, APU는 기본적으로 CPU 코어와 GPU 코어가 같은 실리콘 다이에 위치하는 칩 입니다.

CPU와 GPU (Radeon Vega)를 하나의 실리콘 칩에 탑재한 AMD 사의 Ryzen Accelerated Processing Unit (APU). 하지만 IO-컨트롤러, 통합 메모리 등은 탑재하지 않았다.
그럼에도 아직 애플이 아닌 다른 기업들이 이를 하기 어려운 중요한 이유가 남아 있습니다. SoC는 근본적으로 하나의 온전한 컴퓨터가 들어가 있는 칩 입니다. 때문에 이러한 구조는 근본적으로 Dell, HP와 같은 실제 컴퓨터 제조사에 알맞는 형태입니다. 이를 자동차를 통한 비유로 좀 더 명확하게 설명해 보겠습니다. 여러분의 비즈니스 모델이 자동차 엔진을 만들고 파는 것 이라면, 완전한 자동차를 만들어 파는것과는 아주 큰 사업적인 차이가 있을 것입니다.
반대로 ARM에게 있어서 이는 큰 문제가 아닙니다. Dell이나 HP 같은 컴퓨터 제조사들은 그들이 만드는 SoC의 CPU를 위해 단순히 ARM의 지적 재산권(intelectual property, IP)의 라이센스를 발급받기만 하고, SoC에 필요한 다른 특화된 하드웨어의 IP를 구매해 합치기만 하면 되기 때문이지요. 그리고 나서, GlobalFoundries나 TSMC같이 오늘날 AMD와 애플의 칩을 제조하는 반도체 제조 공정들에게 완성된 디자인을 전달하기만 하면 됩니다.

대만에 있는 TSMC 반도체 파운드리. TSMC는 AMD,애플, Nvidia, 퀄컴 등의 기업을 위해 칩을 제조한다.
여기서 인텔과 AMD의 비즈니스 모델에 큰 문제점이 발생합니다. 그들의 비즈니스 모델은 사람들이 PC의 마더보드에 바로 끼울 수 있는 범용 CPU (general-purpose CPU)를 판매하는 것 입니다. 이 덕분에 컴퓨터 제조사들은 단순히 마더보드, 메모리, CPU, 그래픽 카드를 각각의 제조사로부터 따로 구매하여 하나의 완성 제품으로 판매할 수 있습니다.
하지만 우리는 그러한 세상으로부터 빠르게 바뀌어 가고 있습니다. 새로운 SoC 세계에서는 각각의 제조사에서 만든 서로다른 물리적 구성요소들을 조립하지 않습니다. 그 대신, 여러 제조사들이 가지고 있는 IP (지적 재산권, intellectual property)를 조립하게 됩니다. 제조사들은 그래픽 카드, CPU, 모뎀, IO 컨트롤러, 그리고 SoC에 포함될 수 있는 많은 다른 것 들 각각의 설계 (design)를 구매하여 실제 판매할 SoC를 디자인 하게 됩니다. 그 다음 이를 제조 할 제조공정 (foundary)을 구하게 됩니다.
이제 여기서 큰 문제가 발생합니다. 바로 인텔, AMD, Nvidia는 그들의 지적 재산권을 Dell이나 HP가 그들의 컴퓨터를 위한 SoC를 만들 수 있도록 라이센스를 제공해 주지 않는다는 것 입니다.
물론 인텔과 AMD가 완성품 SoC를 만들어 팔기 시작할 수 도 있습니다. 하지만 그러한 SoC가 무엇을 포함하고 있어야 할까요? PC 제조사들마다 SoC가 가지고 있어야 할 구성 요소에 대한 생각이 다를 수 있습니다. 모든 구성 요소들은 소프트웨어 지원이 필요하기 때문에, 어떠한 특화된 칩들이 포함되어야 되는지에 대해 인텔, AMD, 마이크로소프트, 그리고 PC 제조사들 간의 의견 충돌이 발생할 수 있을 것입니다.
그러나 애플에게 이 문제는 아주 간단합니다. 애플은 모든것을 직접 관리합니다. 예를들어 애플은 개발자들이 머신러닝 관련 코드를 작성할 수 있도록 Core ML 라이브러리를 만들어 제공합니다. Core ML이 애플의 CPU에서 돌아가는지 Neural Engine에서 돌아가는지는 구현 세부사항 (implementation detail)이기 때문에 개발자들은 이에 대해 신경 쓸 필요가 없습니다. (역: 애플은 하드웨어 뿐만 아니라 소프트웨어 및 운영체제 까지 직접 제조한다는 의미)
빠른 CPU를 만드는데 관한 근본적인 어려움
지금까지 요약으로 혼합적인 컴퓨팅 (heterogeneous computing)이 그 이유 중 하나이지만, 온전히 그것 덕분은 아닙니다. Firestorm이라 불리는 M1의 범용 CPU 코어 자체가 매우 빠릅니다. 이 CPU는 과거에는 AMD나 인텔의 코어에 비해 많이 약했던 ARM CPU의 주요 변형판(major deviation) 입니다.
반면에 Firestorm은 대부분의 인텔 코어를 능가하며, 가장 빠른 AMD Ryzen 코어마저 거의 능가하는 모습을 보여줍니다. 이전까지의 상식으로는 이러한 일은 절대 발생하지 않을 것이라 생각되었죠.
무엇이 Firestorm을 빠르게 만드는지를 이야기 하기 전에, CPU를 빠르게 하는 요소들이 무엇이 있는지를 먼저 알아보면 도움이 될 것입니다.
일반적인 통념으로 CPU 속도 증가는 아래 두가지 전략을 조합하여 달성할 수 있습니다.
- 연속된 instruction을 더 빨리 순차적으로 수행
- 동시에 다량의 insruction을 병렬 수행
1980년대로 돌아가 보면, 단순히 클럭 스피드를 높이기만 해도 instruction 수행이 더 빨리 끝났습니다. 한번의 클럭 싸이클 (clock cycle) 마다 컴퓨터는 무언가 하나를 수행하였습니다. 그런데 이 무언가 라는것이 꽤나 작고 사소한 것일 수 있습니다. 때문에 하나의 instruction이 여러개의 더 작은 task(역: 위의 무언가)로 이루어져 있을 수 있기 때문에, 때로는 여러번의 클럭 싸이클을 지나야만 하나의 instruction을 수행할 수 도 있습니다.
하지만 오늘날에는 클럭 스피드를 높이는것이 거의 불가능해 졌습니다. 그것이 바로 지난 몇년간 사람들이 계속해서 이야기 해 오는 “무어의 법칙의 끝”에 관한 것 입니다.
때문에 빠른 CPU를 만드는것은 이제 동시에 최대한 많은 instruction을 수행하는 것에 관한것이 되었습니다.
Multi-core 또는 Out-of-Order processors?
이에 대하여 두가지 접근법이 있습니다.
- CPU 코어 갯수를 더 늘리자. 각각의 코어는 독립적이고 병렬적으로 일한다.
- 각각의 CPU 코어가 동시에 여러개의 instruction을 수행할 수 있게 만들자.
소프트웨어 개발자에게 있어서, 코어 갯수를 늘리는것은 쓰레드 갯수를 늘리는 것과 같습니다. 각각의 CPU 코어는 하드웨어판 쓰레드 처럼 작동합니다.
만약 쓰레드가 무엇인지 모르신다면, 쓰레드는 어떠한 일(task)을 수행하는 하나의 프로세스라고 생각할 수 있습니다. 두개의 코어가 있다면, 하나의 CPU는 두개의 서로다른 일을 동시에(concurrently) 수행할 수 있습니다. 두개의 쓰레드가 있는것 처럼요. task는 두가지 별개의 프로그램이 메모리에 올라가 있거나, 같은 프로그램이 두번 실행되는것으로 생각될 수 있습니다. 각 쓰레드는 현재 프로그램이 실행되고 있는 instruction 위치가 어디인지 등을 저장하는 정보를 저장할 필요가 있습니다. 각 쓰레드는 실행 중간 산물을 개별로 관리하여 저장할 수 도 있습니다.
원칙적으로, 하나의 프로세스는 하나의 코어와 여러개의 쓰레드를 실행할 수 있습니다. 이 경우, 프로세스는 쓰레드를 전환(switch)할 때 현재 실행중인 쓰레드를 정지(halt)하고 진행 상황을 저장합니다. 그리고 나중에 정지되었던 쓰레드로 돌아와 다시 실행하게 됩니다. 그러나 이러한 멀티 쓰레딩은 아래와 같은 경우가 자주 발생하지 않는 이상 그렇게 큰 성능 향상을 가져오지는 않습니다.
- 사용자로부터 입력 값을 대기
- 느린 네트워크 연결로부터 데이터를 수신
이 글에서는 이러한것을 소프트웨어 쓰레드라고 부르기로 하겠습니다. 반대로 하드웨어 쓰레드는 속도를 높이기 위해 실제로 여러개의 물리적 CPU가 사용되는것을 의미합니다.

쓰레드의 문제점은 소프트웨어 개발자가 멀티 쓰레드 코드라고 불리는 형태로 코드를 작성해야 한다는 것 입니다. 이것은 때때로 쉽지 않은 일인데, 옛날에는 이러한 방법이 코드를 작성할때 가장 힘든 일 중 하나이기도 하였습니다. 하지만 서버 소프트웨어를 멀티 쓰레딩으로 만드는것은 상대적으로 쉽게 여겨집니다. 이 경우에는 단순히 각각의 사용자 요청을 처리하는 개별 쓰레드를 만들면 되기 때문이지요. 그렇기 때문에 이 경우 많은 수의 코어를 가지는 것은 성능에 확실히 큰 도움이 됩니다. 특히 클라우드 서비스의 경우 더 그렇습니다.
클라우드 컴퓨팅을 위해 디자인 된 128개의 코어가 장착된 Ampere Altra Max ARM CPU, 이 경우 다수의 하드웨어 쓰레드가 큰 이점이 된다.
그것이 바로 Ampere같은 ARM CPU 제조사들이 Altra Max같이 128개의 코어가 있는 미친 CPU를 만드는 이유입니다. 이 칩은 클라우드를 위해 특별히 만들어 진 칩 입니다. 클라우드 서비스에서는 고성능 싱글코어 성능이 필요하지 않은데, 클라우드 서비스에서는 동일한 소모 전력 대비 최대한 많은 쓰레드를 유지하여 동시에 최대한 많은 사용자의 요청을 처리하는것이 중요하기 때문입니다.
다수의 코어를 가지고 있는 ARM CPU에 관해서 더 알아보고 싶으시다면 다음 글을 읽어보시길 추천드립니다. Are Servers Next for Apple?
이와 반대로 애플은 전혀 반대의 사용성을 가지는 위치에 서있습니다. 애플은 한명의 유저가 사용하는 디바이스를 제조합니다. 다수의 쓰레드를 가지는것은 그다지 이점으로 작용하지 않지요. 애플이 만드는 기기는 게이밍, 영상편집, 개발 등의 작업에 주로 사용이 됩니다. 애플은 아름답고 반응성 있는 그래픽과 애니메이션을 가지는 데스크탑을 원합니다.
데스크탑 어플리케이션은 일반적으로 다수의 코어를 활용할 수 있도록 만들어 지지 않습니다. 예를들어 컴퓨터 게임은 8개 정도의 코어를 통해서는 어느정도 이점을 얻을 수 있지만, 128개의 코어 같은건 그냥 낭비에 불과합니다. 그 대신 갯수는 적더라도 각각의 성능이 더 강력한 코어가 더 적절하지요.
비 순차적 실행 (Out-of-Order Execution) 이 동작하는 방법
더 강력한 성능의 코어를 만들기 위해, 하나의 코어가 더 많은 수의 instruction을 병렬적으로 수행하게 만들 필요가 있습니다. Our-of-Order execution (OoOE)은 멀티 쓰레딩과 같은 기법 없이 동시에 여러 instruction을 수행하는 한가지 방법입니다.
또 다른 방법에 대해 알아보고 싶으시면 다음 글을 읽어보시길 추천드립니다: Very Long Instruction Word Microprocessors
개발자들은 자신의 코드가 OoOE를 활용할 수 있도록 특별히 신경써서 작성해야 할 필요가 없습니다. 개발자의 관점에서 보면 그냥 각각의 코어가 더 빨리 작동하는것처럼 보일 뿐 입니다. 여기서 이 방법은 여러개의 하드웨어 쓰레드를 가지는 것 과는 다른 방법임을 명심해 주세요. 여러분이 해결하고자 하는 문제에 따라, 하드웨어 쓰레드와 OoOE를 둘 다 활용할 수 도 있습니다.
OoOE가 어떻게 작동하는지 알기 위해, 메모리에 관해 몇가지 알아야 할 것들이 있습니다. 특정 메모리 위치 한 곳에 존재하는 데이터의 값을 불러오는것은 느립니다. 하지만 CPU는 한 메모리 위치에서 여러 연속된 바이트를 동시에 불러올 수 있습니다. 따라서 메모리에서 특정 1 바이트를 읽어오는 것은 그 뒤에 붙어서 저장되어 있는 100 바이트를 추가로 더 불러오는 것과 그렇게 큰 차이가 나지 않습니다.

노르웨이에 있는 온라인 상점인 Komplett.no의 창고에 있는 로봇 짐꾼들.
한가지 비유를 들어 보겠습니다. 창고에 있는 짐나르는 로봇을 상상해 봅시다. 위 사진에서처럼 작은 빨간 로봇일 수 있겠지요. 여러곳에 퍼져 있는 장소에 이리저리 옮겨 다니는 것은 시간이 꽤 걸릴 것 입니다. 하지만 서로 인접한 구역에 있는 물건들을 집어 올리는것은 꽤 빨리 할 수 있을 것입니다. 컴퓨터의 메모리 또한 매우 비슷합니다. 서로해 있는 메모리 구역은 그 내용을 빨리 불러 올 수 있습니다.
데이터는 우리가 데이터 버스(databus)라고 부르는 것에 의해 여기저기로 보내 집니다. 이는 메모리와 CPU의 여러 부분에 연결되어 데이터가 옮겨지는 길이나 파이프 정도로 생각할 수 있습니다. 실제로 데이터버스는 그냥 전기를 전도하는 구리 선에 불과합니다. 데이터버스가 충분히 넓으면 동시에 여러 바이트의 데이터를 보낼 수 있습니다.
이를 통해 CPU는 실행해야 할 instruction들을 동시에 왕창 buffer에 받을 수 있습니다. 하지만 그 instruction들은 하나하나 순차적으로 실행되도록 작성되어 있지요. 현대적인 microprocessor들은 Out-of-Order execution (OoOE)라고 불리는 것을 수행합니다.
즉, 현재 CPU에 불러와져 있는 insturction들이 저장되어 있는 buffer를 보며, 어느 것이 어디에 의존성을 가지고 있는지를 빠르게 분석합니다. 아래 예시를 참고해 봅시다.
1 | 01: mul r1, r2, r3 // r1 <- r2 * r3 |
곱셈은 상대적으로 느린 연산입니다. 그러니 한 사이클 이상이 걸린다고 생각해 봅시다. 두번째 instruction에서 연산을 수행하려면 먼저 r1에 저장될 연산 결과를 알아야 하기 때문에, 첫번째 instruction이 끝날 때 까지 그저 기다려야 할 것 입니다.
하지만 03번 줄의 세번째 instruction은 이전 instruction들의 결과에 대해 의존(depend)하고 있지 않습니다. 따라서 비 순차적 실행을 지원하는 프로세서는 03번 insturction을 병렬 수행할 수 있습니다.
그렇지만 우리는 실제로 사용될 수백개의 instruction들을 가지고 이야기를 해야하겠지요? CPU는 그런 insturction들 사이에서의 모든 의존 관계를 알아낼 수 있습니다.
CPU는 각 instruction들의 인풋을 조사함으로써 의존관계를 분석합니다. 인풋이 하나 이상의 다른 instruction의 아웃풋에 의존하는가? 여기서 인풋과 아웃풋은 이전 계산의 결과를 저장하고 있는 레지스터를 의미합니다.
예를들어 add r4, r1, 5 instruction은 r1 레지스터에 저장되어 있는 인풋에 의존하고 있으며, 그 값은 mul r1, r2, r3 instruction을 통해 결정됩니다. 이러한 관계들을 연결하여 아주 길고 복잡한 그래프를 만들 수 있고, CPU는 이 그래프를 활용하게 됩니다.
CPU는 그런 그래프의 노드들을 분석하여 어느 instruction이 병렬 수행 될 수 있고, 어느 지점에서 의존하고 있는 여러개의 연산 결과를 기다려야 하는지를 결정할 수 있습니다.
많은 instruction들이 일찍 실행이 끝나겠지만, 그 결과를 바로 레지스터에 반영할 수는 없습니다. 그랬다가는 연산 결과를 잘못된 순서로 제공해버릴 위험이 있기 때문입니다. (역: 뒤에 끝난 instruction이 오히려 먼저 레지스터에 반영되는 경우) OoOE 밖의 세상에서는, 마치 instruction이 발행된 순서대로 실행 된 것처럼 보여야 합니다.
스택과 같이, CPU는 끝나지 않은 instruction에 닿을 때 까지 완료된 instruction을 위에서부터 순서대로 pop 하게 됩니다.
기본적으로 병렬성은 두가지 형태로 제공됩니다. 개발자가 코드를 작성할 때 명시적으로 다루어야 하는 형태와 완전히 보이지 않는 형태입니다. 물론 두번째 것은 마법과도 같은 비순차 실행을 담당하는 수많은 CPU 트랜지스터에 의존하고 있긴 합니다. 때문에 이는 트랜지스터 수가 적은 작은 사이즈의 CPU에는 적합한 해결책이 아닙니다.
그리고 월등히 좋은 비순차 실행이 바로 M1에 탑재되어 있는 Firestorm 코어가 기똥차게 빠르고 유명해 질 수 있었던 이유입니다. Firestorm의 비 순차 실행은 아마 인텔과 AMD가 절대 따라잡을 수 없을 정도로 그 무엇보다 강력합니다. 왜 그런지를 이해하기 위해 우리는 좀 더 기술적으로 깊게 들어가야 할 필요가 있습니다.
ISA Instructions vs Micro-Operations
이전 파트에서 저는 비 순차적 실행이 어떻게 동작하는지에 관해 몇가지 자세한 사항들을 생략하였습니다.
메모리에 로딩되는 프로그램은 x86, ARM, PowerPC, 68K, MIPS, AVR 등과 같은 특정 Instruction-Set Arcitectures (ISA)를 위해 디자인 된 기계어(machine code)들로 이루어 져 있습니다.
예를들어 24라는 메모리 위치에서 숫자를 레지스터로 불러오는 x86 instruction은 아래와 같이 작성할 수 있습니다.
1 | MOV ax, 24 |
x86은 ax,bx,cx,dx 라고 불리는 레지스터들을 가지고 있습니다 (앞에서 언급했다 시피 이들은 연산 수행 대상이 되는 CPU 내부의 메모리 셀 입니다). 하지만 위와 대등한 코드를 ARM instruction으로 표현하면 다음과 같이 생겼습니다.
1 | LDR r0, 24 |
AMD와 인텔 프로세서는 x86 ISA를 이해하지만, M1과 같은 애플 실리콘 칩은 ARM Instruction-Set Architecture (ISA)를 이해합니다.
하지만 내부적으로 CPU는 프로그래머에게 보이지 않는 완전히 다른 instruction-set을 통해 작동합니다. 이러한 instruction-set은 micro-operations 이라고 불립니다 (micro-ops또는 μops). 이것들이 바로 비 순차적 실행을 하는 하드웨어가 다루는 것 들 입니다.
그런데 왜 OoOE 하드웨어가 그냥 일반적인 기계어 instruction을 다룰 수 없는 것일까요? 그 이유는 바로 CPU가 instruction을 병렬 수행하기 위해서는 아주 많은 별도의 부가 정보를 instruction에 덧붙여 저장해야 하기 때문입니다.
때문에 일만적인 ARM instruction은 32-bit 크기이지만, micro-op은 더 길어질 수 도 있습니다. mirco-op은 자신의 실행 순서 관한 정보도 포함하고 있지요.
1 | 01: mul r1, r2, r3 // r1 <- r2 * r3 |
instruction 01: mul과 03: add를 병렬 수행 하는 경우를 생각해 봅시다. 둘 다 자신의 실행 결과를 레지스터 r1에 저장합니다. 만약 03: add의 실행 결과가 01: mul보다 먼저 쓰여진다면, instruction 02: add는 잘못된 값을 인풋으로 받게 될 것 입니다. 그러므로 instruction의 순서를 추적하는 것은 아주 중요합니다. 각각의 실행 순서는 micro-op에 포함되어 저장됩니다. 또한 instruction 02: add가 01: mul의 아웃풋에 의존하고 있다는 정보 같은것도 함께 저장되게 됩니다.
그리고 이것 왜 micro-ops를 가지고 직접 프로그램을 작성할 수 없는 이유이기도 합니다. micro-ops는 각 microprocessor의 내부적인 세부 정보들을 많이 포함하고 있습니다. 두개의 다른 ARM 프로세서는 완전히 다른 micro-ops를 내부적으로 가질 수 있습니다.
micro-ops 과 관련된 내용에 대해 더 알고 싶으시다면 다음 글을 읽어보시길 추천드립니다: Very Long Instruction Word Microprocessors
또한, micro-ops는 주로 CPU가 다루기에 더 쉽습니다. 왜냐구요? micro-ops는 딱 하나의 간단하고 단순한 일(task)을 수행하기 때문입니다. 일반적인 ISA instruction들은 여러가지 일이 발생하게 하는 더 복잡한 경우가 많고, 때문에 하나 이상의 micro-ops로 번역되는 경우가 많습니다. 따라서 “micro”라는 이름은 그들이 수행하는 작은 일(task) 때문에 붙여진 것이며, 메모리 내의 instruction 크기가 작기 때문에 그렇게 지어진 것이 아닙니다.
CISC CPU들 같은 경우에는 micro-ops 사용하는 것 외에는 거의 다른 대안이 없습니다. 그렇지 않으면 크고 복잡한 CISC instruction들의 특성 때문에 pipeline과 OoOE는 사실상 불가능할 것 이니까요.
RISC CPU들은 다른 선택의 여지가 있습니다. 그래서 예를들어, 작은 ARM CPU같은 경우 micro-ops를 아예 사용하지 않기도 합니다. 하지만 그 경우에 OoOE와 같은 일들을 못하게 됨을 의미합니다.
왜 AMD나 인텔의 OoOE는 M1의 것보다 더 안좋을까?
그런데 이쯤되면 “근데 이게 왜 중요하지?” 라는 생각이 들 수 있겠지요. 이렇게 자세한 내용들이 애플이 AMD와 인텔보다 더 우위에 있는지를 이해하는데 중요할까요?
물론 그렇습니다. 그 이유는 바로 CPU가 빠르게 연산을 수행하는것은 얼마나 빨리 micro-operation들이 저장되는 버퍼를 채울 수 있냐에 달려있기 때문입니다. 만약 더 큰 버퍼를 가지고 있다면 OoOE 하드웨어는 병렬 수행 될 수 있는 instruction들을 더 손쉽게 찾을 수 있을것입니다. 하지만 아무리 큰 instruction 버퍼를 가지고 있다고 하더라도, 버퍼를 빨리 채울 수 없으면 의미가 없겠지요.
instruction 버퍼를 빠르게 채울 수 있는 능력은 기계어(machine code)를 빠르게 micro-ops로 쪼갤 수 있는 능력에 달려 있습니다. 이러한 일을 수행하는 하드웨어 유닛을 decoders 라고 부릅니다.
드디어 M1의 핵심 특징(killer feature)에 대해 이야기 할 차례입니다. 인텔과 AMD의 가장 크고 빠릿한 microprocessor는 열심히 instruction을 micro-ops로 쪼개느라 바쁜 총 4개의 decoder를 가지고 있습니다.
하지만 이 친구들은 M1에게는 적수가 되지 않습니다. M1은 들어보지 못한 숫자의 decoder를 가지고 있지요, 무려 8개 입니다. 이쪽 업계의 그 어느 것들보다 훨씬 더 많은 갯수이지요. 이는 곧 M1이 instruction buffer를 훨씬 더 빨리 채울 수 있음을 의미합니다.
이를 다루기 위해 M1은 또 일반적인 것보다 3배는 더 큰 버퍼를 가지고 있습니다.
왜 인텔과 AMD는 instruction decoder 갯수를 늘릴 수 없을까?
여기가 바로 RISC가 복수를 시작하는 곳이며, M1 Firestorm이 ARM RISC 아키텍처를 채택한게 중요해 지는 순간입니다.
아시다 시피, x86 instruction은 1-15 바이트 사이의 임의의 길이를 가질 수 있습니다. RISC instruction은 고정된 길이를 가집니다. 모든 ARM instruction은 4바이트 길이입니다. 이게 왜 중요할까요?
왜냐하면 모든 instruction들이 같은 길이를 가지는 경우, 연속된 bytes 스트림을 쪼개어 8개의 decoder들에게 병렬적으로 제공하는것은 어렵지 않기 때문입니다.
반면 x86 CPU의 경우, decoder는 어디가 다음 instruction이 시작하는 위치인지를 알 방법이 없습니다. 각 instruction을 분석해서 그 길이가 얼마나 되는지를 실제로 분석하는 수 밖에 없지요. (역: 이때문에 CISC에서는 같은 바이트 값이라도 위치에 따라 다르게 해석된다)
인텔과 AMD가 이를 해결하는 주먹구구식 방법은 그냥 instruction의 시작점으로 가능한 모든 위치로 decode를 시도해 보는 것입니다. 이는 곧 x86 칩들이 수많은 잘못된 예측과 버려야 하는 실수들을 마주해야 함을 의미합니다. 이는 또한 decoder를 더 추가하는게 어려울 정도로 복잡하고 베베 꼬인 decoder 단계를 만들었습니다. 하지만 애플에게 있어서는 decoder를 추가하는게 그렇게 큰 일이 아닙니다.
사실, decoder를 더 추가하는것은 다른 수많은 문제들을 야기하기 때문에, AMD에 따르면 자기들은 사실상 4개가 최대 한계치라고 합니다.
이것이 바로 M1 Firestorm 코어가 AMD와 인텔 CPU와 같은 클럭 스피드인데도 두배나 많은 instruction을 처리할 수 있는 이유입니다.
물론 CISC instruction은 더 많은 수의 micro-ops로 변환된다고 지적할 수 도 있습니다. 예를들어 모든 x86 instruction들이 2개의 micro-ops로 변환되고 ARM instruction은 1개의 micro-ops로 변환된다고 치면, 네개의 x86 decoder는 같은 클럭 싸이클 동안 8개의 decoder가 있는 ARM CPU와 같은 갯수의 micro-ops를 생산할것입니다.
근데 이것마저 실제로는 그렇지 않습니다. 고수준으로 최적화 된 x86코드는 여러개의 micro-ops로 번역되는 복잡한 CISC instruction을 거의 사용하지 않습니다. 사실 대부분은 그냥 1개의 micro-ops로 번역됩니다.
하지만 이러한 모든 복잡하지 않은 x86 instruction은 그다지 인텔과 AMD에게 도움이 되지 않습니다. 왜냐하면 15바이트 크기의 instruction이 흔하지 않다고 하더라도, decoder는 여전히 그것들을 처리할 수 있도록 만들어 져야 하기 때문입니다. 이는 필연적으로 AMD와 Intel이 decoder를 추가하는것을 저해하는 복잡성을 야기합니다.
그래도 AMD의 Zen3 코어는 빠르잖아요 그쵸?
제가 기억하는 바로 성능 벤치마크에 의하면 Zen3라고 불리는 최신 AMD CPU 코어는 Firestorm 코어보다 살짝 더 빠릅니다. 근데 여기서 분위기를 깨는 친구가 있죠. 그건 Zen3 코어가 5 GHz 클럭 스피드를 가지기 때문입니다. Firestorm 코어는 3.2 Ghz 클럭 스피드를 가지고 있습니다. Zen3는 Firestorm보다 60% 빠른 클럭 스피드를 갖고 있음에도 불구하고 아주 살짝 겨우 이기는 정도입니다.
그러면 애플은 왜 클럭 스피드를 더 높이지 않는것일까요? 그 이유는 바로 높은 클럭 스피드는 칩이 열을 더 많이 발생하게 만들기 때문입니다. 이것은 애플이 내세우는 핵심 장점 중 하나입니다. 애플의 컴퓨터는 인텔과 AMD와는 다르게 쿨링이 거의 필요하지 않습니다.
본질적으로, Firestorm 코어는 정말 Zen3 코어보다 더 뛰어나다고 할 수 있겠습니다. Zen3는 더 많은 전류를 소모하고 훨씬 많은 열을 발생시킴으로써 겨우 비비고 있는 중이니까요. 애플은 그냥 그런 선택지를 고르지 않기로 한것입니다.
만약 애플이 더 높은 성능을 원했다면 그냥 더 많은 코어를 추가하였을 것입니다. 이를 통해 와트 사용량은 낮추면서도 더 높은 성능을 제공할 수 있을것입니다.
미래
AMD와 인텔은 자신들 스스로를 두가지 절벽에 몰아넣은 것 처럼 보입니다.
- 그들은 혼합적 컴퓨팅과 SoC 디자인을 쉽게 추구할 수 있는 비즈니스 모델을 가지고 있지 않습니다.
- 그들의 오래된(legacy) x86 CISC instruction set은 이제 OoO 성능을 개선하기 어렵게 만드는, 그들을 쫓는 사냥꾼이 되어버렸습니다.
이에 관한 글: Intel, ARM and the Innovators Dilemma
그래도 이게 게임 오버를 뜻하지는 않습니다. 인텔과 AMD는 클럭 스피드를 높이고, 더 많은 쿨링을 사용하고, 코어 갯수를 높이고, CPU caches를 늘리는 등을 할 수 있습니다. 하지만 둘 모두 불리한 위치에 있는것은 사실입니다. 특히 인텔은 최악의 상황에 놓여있는데, 그들의 코어가 이미 Firestorm한테 가뿐히 패배하였단 점과, 그들이 SoC 솔루션에 포함시킬 수 있는 자체 GPU는 아주 구리다는 것입니다.
또한 더 많은 수의 코어에 투자하는것의 문제는 일반적인 데스크탑 업무에는 많은 수의 코어를 통해서 얻을 수 있는 효과가 극미하다는 점 입니다. 물론 많은 수의 코어가 서버에게는 아주 좋습니다.
그런데 여기서는 또 Amazon이나 Ampere같은 기업들이 128개의 코어를 가진 괴물 CPU로 공세를 가하고 있습니다. 이건 마치 서부전선과 동부전선에서 동시에 전쟁을 치루는 느낌이네요.
하지만 AMD와 인텔에게는 다행스럽게도, 애플은 자기네 칩을 시장에다 직접 판매하지는 않습니다. 그래서 PC 사용자들은 어떻게든 인텔과 AMD가 제공하는것 중에서 골라서 써야하지요. PC 유저들이 아예 다른 배를 타버릴수도 있겠지만(역: 맥 생태계로 넘어간다는 뜻), 그 과정은 아주 느릴것입니다. 이미 많은 돈을 투자한 플랫폼을 쉽게 떠나지는 않으니까요.
그러나 어떤 플랫폼에도 깊게 투자하지 않고 쓸 수 있는 돈이 많은 젊은 전문가들은, 앞으로 점점 더 애플을 사용하며 프리미엄 시장에 대한 그들의 지분을 늘려가고, 결과적으로 전체 PC 시장에서의 이익에서 차지하는 비중을 높일 수도 있을 것입니다. (역: 아직 PC 생태계에 정착하지 않은 돈많은 사람들은 시작부터 애플 생태계로 갈 수도 있으며, 그 숫자가 비중이 커질 수도 있다는 뜻)
요약
- SoC이라서 빠르다.
- Unified Memory
- RAM을 대체할 정도로 빠른 SSD
- 대신 사용자가 직접 업그레이드가 불가능 (근데 맥북은 원래 안되지 않나?)
- ARM 프로세서가 발열이 적어서 GPU가 내는 열을 좀 더 수용할 수 있다.
- OoOE에서 M1이 굉장히 큰 이점을 가지고 있다.
- RISC CPU인 ARM 기반 프로세서 덕분에 decoder 갯수가 훨씬 더 많음
- 이러한 것들은 애플이 하드웨어, 소프트웨어를 모두 직접 만드는 “컴퓨터 제조사”라서 가능한 것!
- 이게 가능한 회사는 현재는 애플밖에 없다.
역시 애플 충성충성!!
바로 M1 맥북 예약구매 하러 갑니다!!
